1. 【事件起因】
今天在做项目的时候,发现提供给客户端的接口时间很慢,达到了2秒多,我第一时间,抓了接口,看了运行的sql,发现就是 2个sql慢,分别占了1秒多。
一个sql是 链接了5个表同时使用了 2个 order by和 1个limit的分页 sql。
一个sql是上一个sql的count(*),即链接了5个表,当然没有limit了(取总数)。
2. 【着手优化】
1)【优化思路】
第一条是 做client调用 service层的数据缓存
第二条就是 优化sql本身。
这里着重讲一下 优化sql本身
2)【使用expain】
使用 explain语句,查看该语句,
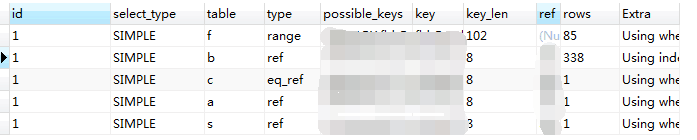
看着没有啥毛病啊,使用到了索引,扫描的行数也多,一个 85行,一个338多行,其他的也都是 1行。
3)【使用子查询优化】
使用子查询进行优化,效果差不多,只能想别的办法
4)【去掉order by排序】
和同事讨论时,觉得原来的5张表该加的索引都加了,为什么速度慢呢,我说里面还做了排序处理。
说者无心,听者有意。他说 你去掉排序试试,果然,去掉排序后,时间降到了 0.002秒,快了很多。
但是order by排序为什么很慢呢,因为 order by的那个字段也是 有索引的。
5)【创建联合索引】
后来查询了下面这篇文章( )才知道, 如果查询出来的数据量很大的时候,order by字段,必须和前面的where语句中的字段建立 联合索引才行,同事建立的索引顺序还得是 先是 where语句中的字段最后是 order by中的字段。
6)【最终方案】
明白了道理,但是鉴于还得麻烦 DBA创建索引为 特定项目建立特定的索引也不划算。这部分数据一遍不经常变动,可以做成缓存的形式,就作罢了,但是 分析问题的思路和优化 sql order的过程还是有收获的
3. 【参考资料】
1)
2)
转载,原出处